Алгоритм-дешифровщик, представленный американскими учеными, работает по новому принципу. На смену параллельным корпусам, которые используются в классическом машинном переводе, пришел анализ сходных лексем родственных языков.
При работе с параллельными текстами система обучается благодаря уже имеющимся примерам переводов. Но когда речь идет о древних текстах, у которых не существует примеров перевода, процесс усложняется. Требуется глубокий анализ: определение родственных языков, предположения о написанном на основе исторических данных, сравнение с другими текстами того же времени. Такой метод уже использовался при работе с системами автоматической расшифровки языка, но результаты не всегда были достаточно точны и зависели от определенного языка.
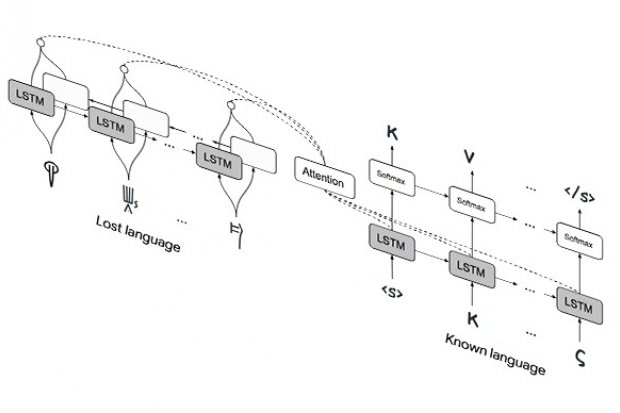
Представленная исследователями Массачусетского технологического института система способна дешифровать любой язык без использования параллельных корпусов, основываясь на работе рекуррентных нейросетей с долгой краткосрочной памятью. Система получает текст на неизвестном и его известном родственном языках, составляет словарь соответствий и на основе них определяет пары когнатов.
Алгоритм уже обучили и опробовали для расшифровки угаритского письма на основе иврита и линейного письма Б на основе древнегреческого. Также определили когнаты между испанским, итальянским и португальским. В среднем точность работы системы достигает 90%.
В дальнейшем планируется использовать новый алгоритм для языков, которые еще не были дешифрованы, к примеру, линейное письмо А.
Комментарии 0